I've been scanning and organizing my family's photo archive for the last 10 years or so. Tens of thousands of images going back decades. Slides, negatives, prints, the works. One of the biggest problems is that they have so little data. I have to bug family members to identify people and places from before I was born or when I was little. And I'm a completionist. I like all my metadata filled in. I would have boxes labeled "somewhere in Europe, maybe 1987?"
With AI, I figured at least some of that could be automated. So I built PhotoContext. It's a Lightroom plugin that sends your photo to an AI vision model and asks "where was this taken?"
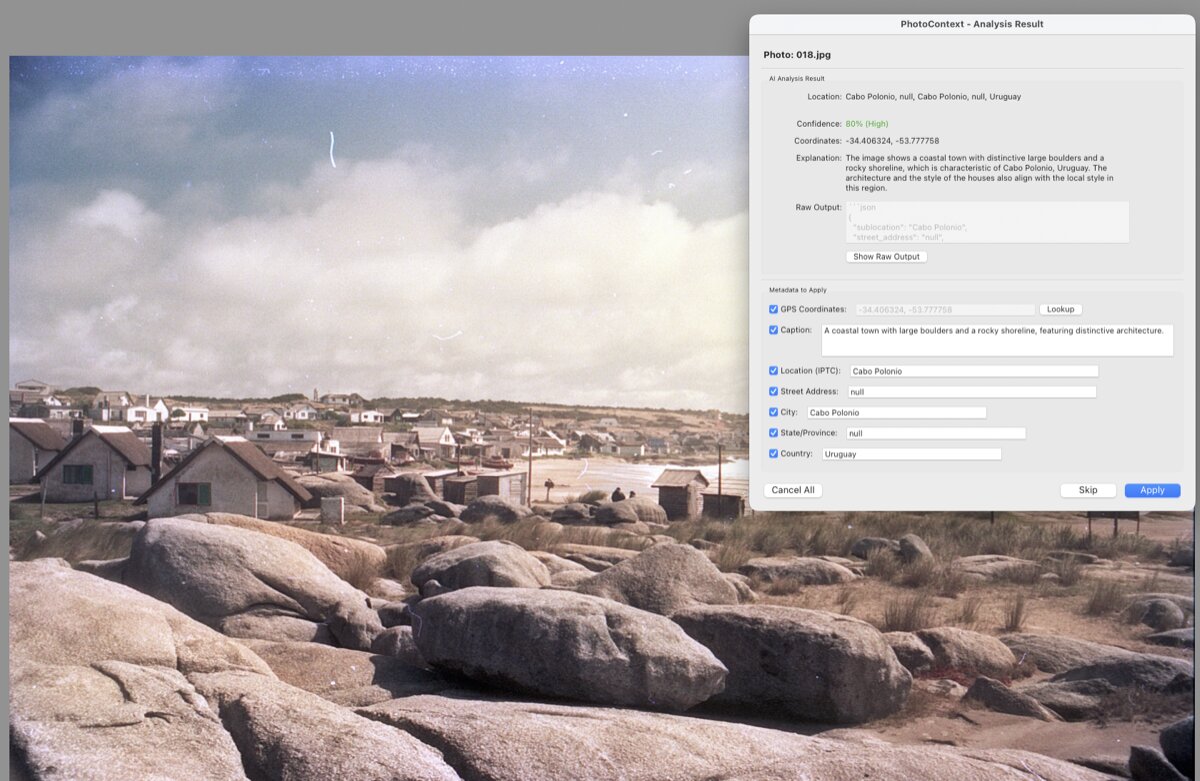
PhotoContext identifying Cabo Polonio, Uruguay from a scanned photo. 80% confidence, GPS coordinates, IPTC metadata, all ready to apply.
What it does
The plugin recognizes landmarks, signs, architecture, and landscapes, then writes the GPS coordinates and location metadata directly into Lightroom. Not just coordinates. It fills in city, state/province, country, IPTC location fields, and generates a caption describing what the AI sees in the image. One click, all the metadata.
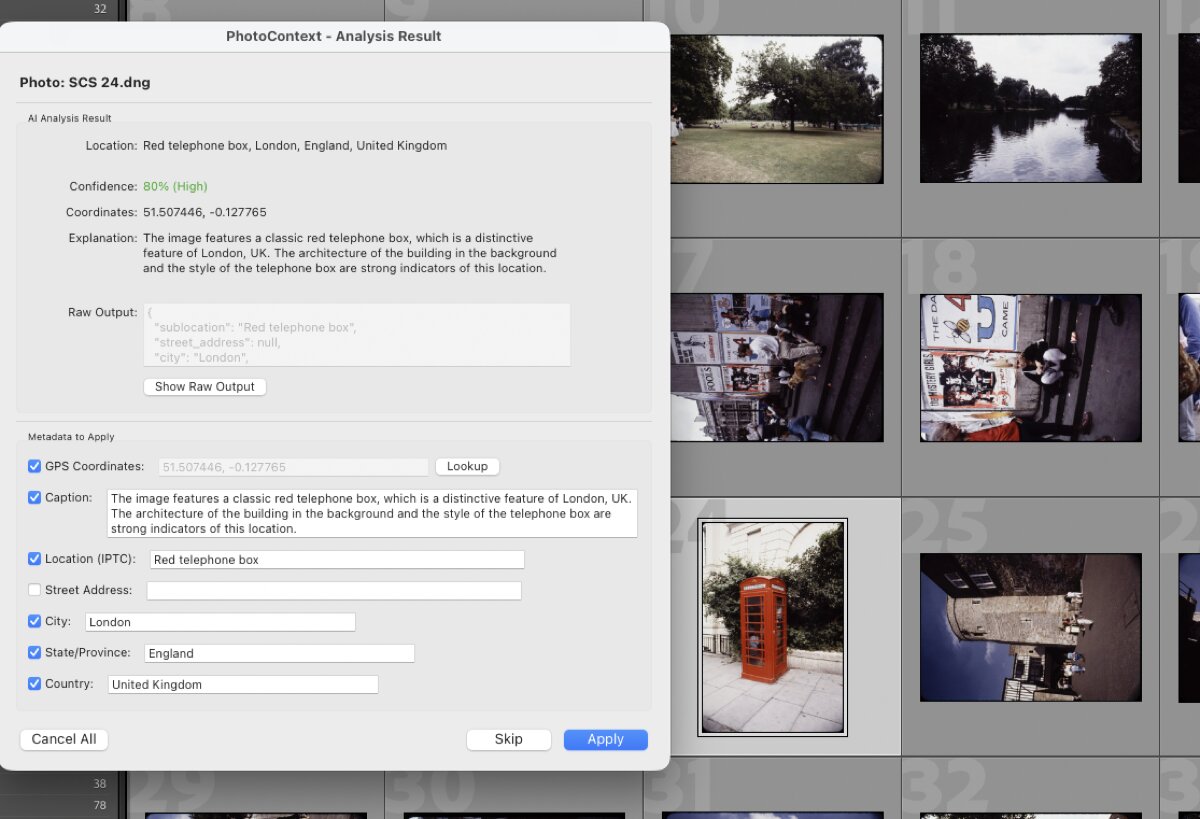
A London phone box. The AI picks up the architecture, the phone box style, and fills in everything from GPS to country.
You can process photos one at a time or in batches. Select 50 photos, hit analyze, and it works through them with a dialog for each one where you can review, edit, skip, or apply the results.
Is it perfect?
No. Sometimes it confidently tells me a photo of my vacation in Uruguay is in Sweden. But here's the thing: you can give it a hint like "Portugal, 1970s" and it course-corrects pretty well. It's not going to recognize the inside of your kitchen, but it does a solid job with landscapes, landmarks, and even famous people. So if you're famous, you'll get even better captions.
The coordinates land right on Cabo Polonio. When it works, it really works.
How it works
The plugin is written in Lua (Lightroom's SDK language) and talks to a Python backend running FastAPI. The backend sends the image to an AI vision model via OpenRouter, so you can pick your model: GPT-4o, Claude, Gemini, or free ones like Qwen. The model analyzes the image and returns structured JSON with location data, confidence, and an explanation of its reasoning.
The backend converts the location into GPS coordinates using geocoding, and the plugin writes everything back into Lightroom's catalog. Photos show up on the map module immediately.
It costs about $0.001 per photo with paid models. That's 1,000 photos for a dollar. The free Qwen model works pretty damn well too, and unless you're tagging over 50 a day, it's honestly not worth paying for a premium model.
The product side
This isn't a side project sitting on GitHub. It's a shipped product with a license system, a product website, Stripe payments, and real users. There's a free trial (5 photos per session) and a one-time license for the full version.
Building the license infrastructure was its own project: key generation, activation validation, update distribution. Not glamorous work, but it's the difference between a demo and a product.
What's next
The next version will add tagged people's names to the captions. If Lightroom already knows who's in the photo (face tagging), PhotoContext will include their names in the generated caption and metadata. Still working on that one.
Llevo unos 10 años escaneando y organizando el archivo fotográfico de mi familia. Decenas de miles de imágenes de décadas atrás. Diapositivas, negativos, copias en papel, de todo. Uno de los mayores problemas es que tienen muy pocos datos. Tengo que molestar a familiares para que identifiquen personas y lugares de antes de que yo naciera o de cuando era pequeño. Y soy perfeccionista. Me gusta tener todos los metadatos completos. Tenía cajas etiquetadas como «en algún lugar de Europa, quizás 1987».
Con la IA, pensé que al menos parte de eso podría automatizarse. Así que construí PhotoContext. Es un plugin de Lightroom que envía tu foto a un modelo de visión por IA y pregunta «¿dónde se tomó esta foto?»
PhotoContext identificando Cabo Polonio, Uruguay a partir de una foto escaneada. 80% de confianza, coordenadas GPS, metadatos IPTC, todo listo para aplicar.
Qué hace
El plugin reconoce monumentos, carteles, arquitectura y paisajes, y luego escribe las coordenadas GPS y los metadatos de ubicación directamente en Lightroom. No solo coordenadas. Rellena ciudad, estado/provincia, país, campos de ubicación IPTC, y genera un pie de foto describiendo lo que la IA ve en la imagen. Un clic, todos los metadatos.
Una cabina telefónica de Londres. La IA detecta la arquitectura, el estilo de la cabina, y rellena todo desde el GPS hasta el país.
Puedes procesar fotos de una en una o por lotes. Selecciona 50 fotos, pulsa analizar, y las va procesando con un diálogo para cada una donde puedes revisar, editar, saltar o aplicar los resultados.
¿Es perfecto?
No. A veces me dice con total seguridad que una foto de mis vacaciones en Uruguay fue tomada en Suecia. Pero la cuestión es que puedes darle una pista como «Portugal, años 70» y se corrige bastante bien. No va a reconocer el interior de tu cocina, pero hace un trabajo sólido con paisajes, monumentos e incluso personas famosas. Así que si eres famoso, obtendrás pies de foto aún mejores.
Las coordenadas caen justo en Cabo Polonio. Cuando funciona, funciona de verdad.
Cómo funciona
El plugin está escrito en Lua (el lenguaje del SDK de Lightroom) y se comunica con un backend en Python que ejecuta FastAPI. El backend envía la imagen a un modelo de visión por IA a través de OpenRouter, por lo que puedes elegir tu modelo: GPT-4o, Claude, Gemini, o gratuitos como Qwen. El modelo analiza la imagen y devuelve un JSON estructurado con datos de ubicación, nivel de confianza y una explicación de su razonamiento.
El backend convierte la ubicación en coordenadas GPS mediante geocodificación, y el plugin escribe todo de vuelta en el catálogo de Lightroom. Las fotos aparecen en el módulo de mapa inmediatamente.
Cuesta alrededor de 0,001 $ por foto con modelos de pago. Eso son 1.000 fotos por un dólar. El modelo gratuito Qwen también funciona muy bien, y a menos que etiquetes más de 50 al día, sinceramente no merece la pena pagar por un modelo premium.
El lado de producto
Esto no es un proyecto secundario en GitHub. Es un producto publicado con un sistema de licencias, un sitio web de producto, pagos con Stripe y usuarios reales. Hay una prueba gratuita (5 fotos por sesión) y una licencia de pago único para la versión completa.
Construir la infraestructura de licencias fue un proyecto en sí mismo: generación de claves, validación de activaciones, distribución de actualizaciones. No es trabajo glamuroso, pero es lo que marca la diferencia entre una demo y un producto.
Próximos pasos
La próxima versión añadirá los nombres de las personas etiquetadas a los pies de foto. Si Lightroom ya sabe quién aparece en la foto (etiquetado facial), PhotoContext incluirá sus nombres en el pie de foto generado y en los metadatos. Todavía estoy trabajando en eso.