Hundreds of thousands of digital files piled up over decades. Photos across dozens of folders, documents scattered through drives, videos with no labels, health records buried in downloads. Years of data with no structure, no connections, and no way to find anything.
This isn't a client project. It's my own data — and no existing app could handle the scale or the mess. So I built the system myself.
El problema
Cientos de miles de archivos digitales acumulados durante décadas. Fotos repartidas en docenas de carpetas, documentos dispersos en distintos discos, vídeos sin etiquetar, historiales médicos enterrados en la carpeta de descargas. Años de datos sin estructura, sin conexiones y sin forma de encontrar nada.
Esto no es un proyecto para un cliente. Son mis propios datos, y ninguna aplicación existente podía manejar ni la escala ni el desorden. Así que construí el sistema yo mismo.
The challenge
This wasn't a simple "upload and tag" problem. People accumulate massive amounts of data across every part of their lives — personal and professional — with no consistent naming, no metadata, and no organization:
Family photos and home videos scattered across phones, drives, and old backups
Emails, chat histories, and message threads across apps and platforms
Tax returns, insurance policies, contracts, and legal documents
Medical records, lab results, prescriptions
Diplomas, transcripts, certifications, and training materials
Work projects, presentations, reports, and client files
Receipts, warranties, manuals, and purchase records
Personal writing, journals, correspondence
Collections, inventories, catalogs
BackIt crawls apps, inboxes, drives, and local folders — pulling in all of it. It also handles digitized physical media like scanned letters, old prints, and handwritten documents in any language. And everything stays private: no cloud, no third-party services, nothing leaves your network.
El reto
No se trataba de un simple problema de «subir y etiquetar». Las personas acumulan cantidades enormes de datos en todos los ámbitos de su vida — personal y profesional — sin nombres coherentes, sin metadatos y sin ninguna organización:
Fotos familiares y vídeos caseros repartidos entre móviles, discos duros y copias de seguridad antiguas
Correos electrónicos, historiales de chat e hilos de mensajes en distintas aplicaciones y plataformas
Declaraciones de la renta, pólizas de seguros, contratos y documentos legales
Historiales médicos, resultados de laboratorio, recetas
Diplomas, expedientes académicos, certificaciones y materiales de formación
Proyectos de trabajo, presentaciones, informes y archivos de clientes
Recibos, garantías, manuales y comprobantes de compra
Escritos personales, diarios, correspondencia
Colecciones, inventarios, catálogos
BackIt rastrea aplicaciones, bandejas de entrada, discos y carpetas locales — recopilándolo todo. También procesa material físico digitalizado como cartas escaneadas, copias antiguas y documentos manuscritos en cualquier idioma. Y todo se mantiene privado: sin nube, sin servicios de terceros, nada sale de tu red.
Timeline on mobile.
Stories on mobile.
Línea de tiempo en el móvil.
Historias en el móvil.
What BackIt does
BackIt crawls everything — files, folders, apps, inboxes — and builds a fully organized, searchable archive. Every item is categorized, tagged with metadata, and archived with the care of a museum collection. Documents get read automatically, even handwritten ones, in any language. Photos are analyzed for locations, faces, and scenes. Nothing gets lost.
Qué hace BackIt
BackIt rastrea todo — archivos, carpetas, aplicaciones, bandejas de entrada — y construye un archivo completamente organizado y con capacidad de búsqueda. Cada elemento se clasifica, se etiqueta con metadatos y se archiva con el cuidado de una colección de museo. Los documentos se leen automáticamente, incluso los manuscritos, en cualquier idioma. Las fotos se analizan para detectar ubicaciones, rostros y escenas. Nada se pierde.
The Archive
The foundation. Every file you own — photos, documents, videos, emails, chats, records — properly categorized, enriched with metadata, and stored in a structured archive. Think of it as a personal museum for your entire digital life. Browse by category, search by content, filter by date. Everything in one place, everything findable.
El archivo
La base de todo. Cada archivo que posees — fotos, documentos, vídeos, correos electrónicos, chats, registros — debidamente clasificado, enriquecido con metadatos y almacenado en un archivo estructurado. Piensa en ello como un museo personal de toda tu vida digital. Navega por categoría, busca por contenido, filtra por fecha. Todo en un solo lugar, todo localizable.
Stories
BackIt doesn't just store your data — it reads it and creates stories from it. By connecting photos, documents, dates, and context, it automatically generates narrative posts about moments in your life. "The day Sam was born." "John's graduation." "Summer in Paris, 2003." Stories you never had time to write, assembled from data you already had.
Historias
BackIt no solo almacena tus datos — los lee y crea historias a partir de ellos. Conectando fotos, documentos, fechas y contexto, genera automáticamente relatos narrativos sobre momentos de tu vida. «El día que nació Sam.» «La graduación de Juan.» «Verano en París, 2003.» Historias que nunca tuviste tiempo de escribir, elaboradas a partir de datos que ya tenías.
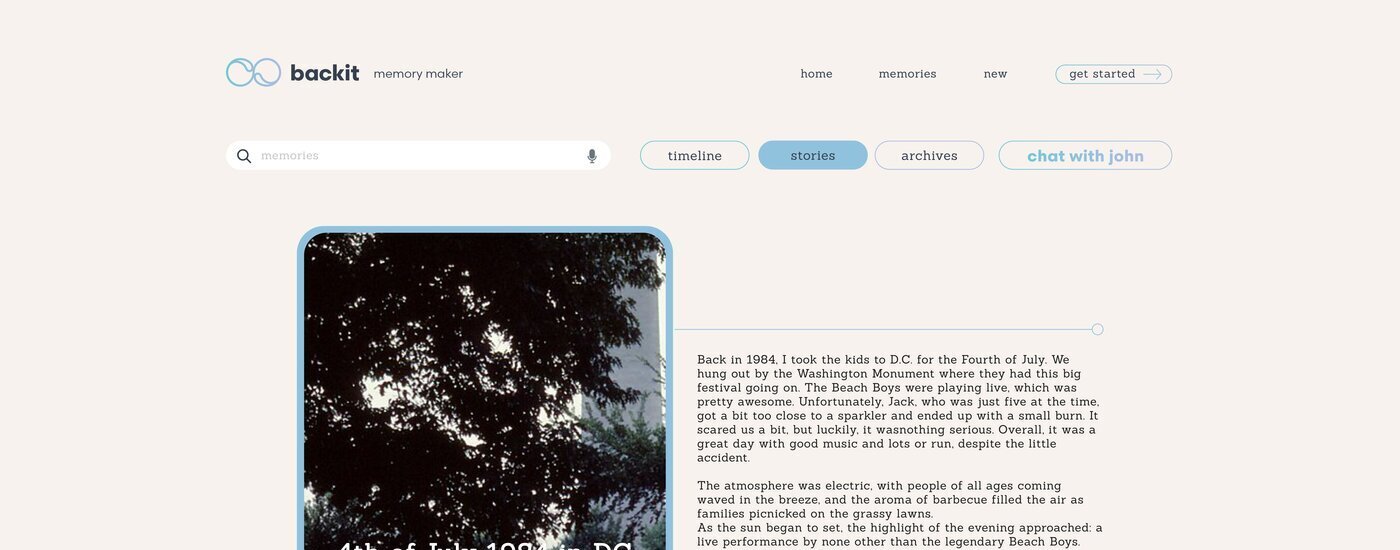
"4th of July 1984 in DC" — a story assembled automatically from photos, documents, and dates already in the archive. Browse more stories in the carousel below.
«4 de julio de 1984 en Washington D. C.» — una historia elaborada automáticamente a partir de fotos, documentos y fechas ya presentes en el archivo. Explora más historias en el carrusel de abajo.
Auto-edited Videos
Like stories, but in motion. BackIt pulls together photos, video clips, documents, and audio from across the archive and assembles edited videos automatically. A highlight reel of a vacation. A tribute for a birthday. A year in review. No editing software, no manual work — just the finished product, ready to share.
Vídeos editados automáticamente
Como las historias, pero en movimiento. BackIt reúne fotos, clips de vídeo, documentos y audio de todo el archivo y monta vídeos editados automáticamente. Un resumen de unas vacaciones. Un homenaje para un cumpleaños. Un repaso del año. Sin software de edición, sin trabajo manual — solo el producto terminado, listo para compartir.
Chat with the Archive
This is where it gets personal. BackIt includes a conversational chatbot trained on the entire archive. Ask it anything: "When did we move to the new house?" "What did Dad do for work in the 80s?" "Show me everything from our trip to Italy." It's like talking to someone who remembers everything — because it has access to every photo, every document, every record. A digital version of the archive's owner, available to anyone in the family.
Chatea con el archivo
Aquí es donde se vuelve personal. BackIt incluye un chatbot conversacional entrenado con todo el archivo. Pregúntale lo que quieras: «¿Cuándo nos mudamos a la casa nueva?» «¿A qué se dedicaba papá en los 80?» «Enséñame todo del viaje a Italia.» Es como hablar con alguien que lo recuerda todo — porque tiene acceso a cada foto, cada documento, cada registro. Una versión digital del propietario del archivo, disponible para cualquier miembro de la familia.
Timeline
A visual, filterable timeline of an entire life. Every event, every document, every photo — laid out chronologically. Filter by person, by category, by date range. Zoom into a single week or zoom out to see decades. It turns a messy pile of data into a clear, navigable history.
Línea de tiempo
Una línea de tiempo visual y filtrable de toda una vida. Cada evento, cada documento, cada foto — dispuestos cronológicamente. Filtra por persona, por categoría, por rango de fechas. Haz zoom en una semana concreta o aléjate para ver décadas enteras. Convierte un montón desordenado de datos en una historia clara y navegable.
Stack
Tecnologías
PythonTesseract OCRGPT-4 / Local LLMsChromaDBFastAPISQLiteFFmpegLinux / Nginx
Where it stands
Hundreds of thousands of items — indexed, searchable, and connected
Stories and videos generated automatically from archived data
Conversational chatbot that knows the entire archive
Full timeline of a life, filterable by person, category, or date
Reads documents in any language, including faded handwriting
Completely private — runs on local hardware, nothing in the cloud
Always growing — new material is automatically sorted and processed
Estado actual
Cientos de miles de elementos — indexados, con capacidad de búsqueda y conectados entre sí
Historias y vídeos generados automáticamente a partir de datos archivados
Chatbot conversacional que conoce todo el archivo
Línea de tiempo completa de una vida, filtrable por persona, categoría o fecha
Lee documentos en cualquier idioma, incluida escritura manuscrita desvanecida
Completamente privado — funciona en hardware local, nada en la nube
En constante crecimiento — el nuevo material se clasifica y procesa automáticamente
Why this matters beyond my family
Every organization sitting on years of unstructured material has this same problem. Law firms with boxes of case files. Medical practices with decades of patient records. Museums with uncataloged collections. Media companies with vast photo and video libraries. Family offices managing generations of documents.
The specific material changes, but the need is the same: make it findable, make it searchable, make it useful. That's what this system does — and it's the kind of system I build.
Por qué esto importa más allá de mi familia
Toda organización que lleve años acumulando material no estructurado tiene este mismo problema. Despachos de abogados con cajas de expedientes. Consultas médicas con décadas de historiales de pacientes. Museos con colecciones sin catalogar. Empresas de comunicación con enormes archivos fotográficos y de vídeo. Family offices que gestionan documentos de varias generaciones.
El material concreto cambia, pero la necesidad es la misma: hacerlo localizable, hacerlo buscable, hacerlo útil. Eso es lo que hace este sistema, y es el tipo de sistema que yo construyo.
Sitting on a collection that needs to become searchable?